Topic of Contents
-
Molecular Biology is a subject to characterize the structural and functional relationships between nucleic acids and proteins.
-
Central Dogma

-
Genes influence the development of phenotypes.
-
Polynucleotides provide the sequence information, while proteins provide most of the catalytic functions that serve to bring about the synthesis of more polynucleotides and proteins of the same types
-
DNA is passed between generations through semi-conservative replication, while maintaining the stability of genetic information in a double helix structure.
- The brief structure of DNA

- The values and ranges of atomic sizes, bond lengths, and bond angles between atoms determine the basic shape and degrees of freedom of the spatial structure.

-
Why does the DNA helix twist to the right instead of the left?
The answer is generated by GPT-3.5-Turbo
Answer: The DNA helix twists to the right due to the chirality of the deoxyribose sugar molecules in the DNA backbone. The deoxyribose sugars in DNA are in the D-configuration, which causes the helix to naturally twist in a right-handed direction. This chirality of the sugar molecules dictates the direction of the helical twist in DNA.

-
Various conformations of nucleic acids - Z fold and B fold
The answer is generated by GPT-4o-mini
Z-DNA and B-DNA are two different DNA double helix structures, and their main structural differences lie in the twisting direction of the DNA and the interactions between the base pairs.
B-DNA is the most common DNA structure, with a right-handed helix, where the base pairs are interconnected through hydrogen bonds. In contrast, Z-DNA has a left-handed helix, and the interactions between the base pairs are more complex, involving hydrogen bonds, ionic bonds, and stacking interactions. These different modes of interaction lead to the structural differences between Z-DNA and B-DNA.
Additionally, Z-DNA usually forms in specific sequences or structures, such as in DNA supercoils, negative supercoiled regions, or sequences rich in GC base pairs. These specific sequences and structures are also among the reasons for the structural differences between Z-DNA and B-DNA.

-
Why is DNA the primary genetic material?
The answer is generated by GPT-3.5-Turbo
DNA is the primary genetic material in most organisms because of its unique properties that make it well-suited for storing and transmitting genetic information. Some key reasons why DNA is the primary genetic material include:
-
Stability: DNA is a stable molecule due to its double-stranded structure and the presence of hydrogen bonds between complementary base pairs. This stability helps ensure the accurate transmission of genetic information from one generation to the next.
-
Replication: DNA can be accurately replicated through the process of DNA replication, where each strand serves as a template for the synthesis of a new complementary strand. This allows for faithful transmission of genetic information during cell division.
-
Information storage: DNA has a linear sequence of nucleotide bases (adenine, thymine, cytosine, and guanine) that encode the genetic information. This sequence can be transcribed into RNA and translated into proteins, allowing for the expression of genes and the functioning of cells.
-
Mutability: While DNA is stable, it also allows for genetic variation through mutations, which can arise due to errors in replication, exposure to mutagens, or other factors. This genetic variability is important for evolution and adaptation to changing environments.
Overall, DNA’s stability, replicative capacity, information storage capabilities, and mutability make it a highly effective molecule for serving as the primary genetic material in living organisms.
-
Volcabulary
| English | Chinese |
|---|---|
| bacteriophage | 噬菌体 |
| nucleic acids | 核酸 |
| double helix | 双螺旋 |
| polynucleotide | 多聚核苷酸 |
| hydrophilic | 亲水的 |
| hydrophobic | 疏水的 |
| polymerase | 聚合酶 |
| pyrimidine | 嘧啶 |
| purine | 嘌呤 |
| Adenine | 鸟嘌呤 |
| Guanine | 腺嘌呤 |
| Thymine | 胞嘧啶 |
| Cytosine | 胸腺嘧啶 |
| Uracil | 尿嘧啶 |
| glycosidic bond | 糖苷键 |
| phosphate bond | 磷酸酯键 |
Translation
The first slide corresponds to Chapters 1 and 2 of the textbook.
Chapter 1 The Mendelian View of the world
孟德尔的世界观
Original Text
Heredity is controlled by chromosomes, which are the cellular carriers of genes. Hereditary factors were first discovered and described by Mendel in 1865, but their importance was not realized until the start of the 20th century. Each gene can exist in a variety of different forms called alleles. Mendel proposed that a hereditary factor (now known to be a gene) for each hereditary trait is given by each parent to each of its offspring. The physical basis for this behavior is the distribution of homologous chromosomes during meiosis: one (randomly chosen) of each pair of homologous chromosomes is distributed to each haploid cell. When two genes are on the same chromo- some, they tend to be inherited together (linked). Genes affecting different characteristics are sometimes inherited independently of each other, because they are located on different chromosomes. In any case, linkage is seldom complete because homologous chromosomes attach to each other during meiosis and often break at identical spots and rejoin crossways (crossing over). Crossing over transfers genes initially located on a paternally derived chromosome onto gene groups originating from the maternal parent.
Different alleles from the same gene arise by inheritable changes (mutations) in the gene itself. Normally, genes are extremely stable and are copied exactly during chromosome duplication; mutation occurs only rarely and usually has harmful consequences. Mutation does, however, play a positive role, because the accumulation of rare favorable mutations provides the basis for genetic variability that is presupposed by the theory of evolution.
For many years, the structure of genes and the chemical ways in which they control cellular characteristics were a mystery. As soon as large numbers of spontaneous mut tions had been described, it became obvious that a one gene – one characteristic relationship does not exist and that all complex characteristics are under the control of many genes. The most sensible idea, postulated by Garrod in 1909, was that genes affect the synthesis of enzymes. However, the tools of Mendelian geneticists—organisms such as the corn plant, the mouse, and even the fruit fly Drosophila—were not suitable for detailed chemical investigations of gene – protein relations. For this type of analysis, work with much simpler organisms was to become indispensable.
Translated Text
遗传是由染色体控制的,染色体是基因的细胞载体。遗传因素最早由孟德尔在1865年发现和描述,但直到20世纪初才意识到它们的重要性。每个基因可以存在多种不同形式,称为等位基因。孟德尔提出,每个遗传特征的遗传因子(现在被称为基因)是由每个父母传递给每个后代的。这种行为的物理基础是减数分裂期间同源染色体的分布:每对同源染色体中的一个(随机选择)分配给每个单倍体细胞。当两个基因位于同一染色体上时,它们倾向于一起遗传(连锁)。影响不同特征的基因有时会独立遗传,因为它们位于不同的染色体上。无论如何,连锁很少是完全的,因为同源染色体在减数分裂期间相互连接,并经常在相同的位置断裂并交叉重组(交叉互换)。交叉互换将最初位于父源染色体上的基因转移到母源染色体上的基因组。
同一基因的不同等位基因是通过基因本身的可遗传变化(突变)产生的。通常,基因非常稳定,在染色体复制期间被精确复制;突变很少发生,通常会产生有害后果。然而,突变也发挥着积极作用,因为罕见有利突变的积累为进化理论所预设的遗传变异性提供了基础。
多年来,基因的结构以及它们控制细胞特征的化学方式一直是一个谜。当大量自发突变被描述后,很明显一个基因对应一个特征的关系并不存在,所有复杂特征都受到许多基因的控制。加罗德在1909年提出的最合理的想法是基因影响酶的合成。然而,孟德尔遗传学家使用的工具——如玉米植物、小鼠,甚至果蝇 Drosophila——并不适合用于基因-蛋白质关系的详细化学研究。对于这种类型的分析,与更简单的生物一起工作将变得不可或缺。
Chapter 2 Nucleic Acids Convey Genetic Information
Original Text
The discovery that DNA is the genetic material can be traced to experiments performed by Griffith, who showed that nonvirulent strains of bacteria could be genetically transformed with a substance derived from a heat-killed pathogenic strain. Avery, McCarty, and MacLeod subsequently demonstrated that the transforming substance was DNA. Further evidence that DNA is the genetic material was obtained by Hershey and Chase in experiments with radiolabeled bacteriophage. Building on Chargaff ’s rules and Franklin and Wilkins’ X-ray diffraction studies, Watson and Crick proposed a double-helical structure of DNA. In this model, two polynucleotide chains are twisted around each other to form a regular double helix. The two chains within the double helix are held together by hydrogen bonds between pairs of bases. Adenine is always joined to thymine, and guanine is always bonded to cytosine. The existence of the base pairs means that the sequence of nucleotides along the two chains are not identical, but complementary. The finding of this relationship suggested a mechanism for the replication of DNA in which each strand serves as a template for its complement. Proof for this hypothesis came from (a) the observation of Meselson and Stahl that the two strands of each double helix separate during each round of DNA replication, and (b) Kornberg’s discovery of an enzyme that uses single-stranded DNA as a template for the synthesis of a complementary strand.
As we have seen, according to the “central dogma” information flows from DNA to RNA to protein. This transformation is achieved in two steps. First, DNA is transcribed into an RNA intermediate (messenger RNA), and second, the mRNA is translated into protein. Translation of the mRNA requires RNA adaptor molecules called tRNAs. The key char- acteristic of the genetic code is that each triplet codon is recognized by a tRNA, which is associated with a cognate amino acid. Out of 64 (4 $\times$ 4 $\times$ 4) potential codons, 61 are used to specify the 20 amino acid building blocks of proteins, whereas 3 are used to provide chain-terminating signals. Knowledge of the genetic code allows us to predict protein-coding sequences from DNA sequences. The advent of rapid DNA sequencing methods has ushered in a new era of genomics, in which complete genome sequences are being determined for a wide variety of organisms, including humans. Comparing genome sequences offers a powerful method to identify critical regions of the genome that encode not only important elements of proteins but also regulatory regions that control the expression of genes and the duplication of the genome.
Translated Text
DNA 被确认为遗传物质的发现可以追溯到由格里菲斯进行的实验,他展示了非致病菌株可以通过来自热杀死的致病菌株的物质进行遗传转化。埃弗里、麦卡蒂和麦克劳德随后证明了这种转化物质就是 DNA 。赫希和查斯在用放射性标记的噬菌体进行实验中获得了进一步证据,证明了 DNA 是遗传物质。在查尔格夫的规则以及富兰克林和威尔金斯的X射线衍射研究的基础上,沃森和克里克提出了 DNA 的双螺旋结构。在这个模型中,两条多核苷酸链缠绕在一起形成一个规则的双螺旋。双螺旋内的两条链通过碱基对之间的氢键相互连接。腺嘌呤总是与胸腺嘧啶结合,鸟嘌呤总是与胞嘧啶结合。碱基对的存在意味着两条链上的核苷酸序列并不相同,而是互补的。这种关系的发现暗示了 DNA 复制的机制,其中每条链都作为其互补链的模板。这一假设的证据来自于(a)梅瑟森和斯托尔观察到每轮 DNA 复制时双螺旋的两条链会分离,以及(b)科恩伯格发现了一种酶,该酶利用单链 DNA 作为合成互补链的模板。
正如我们所见,根据“中心法则”,信息从 DNA 流向 RNA 再到蛋白质。这一转化分为两步。首先,DNA被转录成RNA中间体(信使RNA),然后,mRNA 被翻译成蛋白质。mRNA 的翻译需要称为tRNA的RNA适配分子。遗传密码的关键特征是每个三联密码子被一个与之相关的氨基酸结合的tRNA所识别。在 64 个(4 $\times$ 4 $\times$ 4)潜在密码子中,有61个用于指定蛋白质的20种氨基酸构建块,而另外3个用于提供链终止信号。对遗传密码的了解使我们能够从DNA序列中预测蛋白质编码序列。快速 DNA 测序方法的出现开启了基因组学的新时代,各种生物体的完整基因组序列正在被确定,包括人类。比较基因组序列提供了一个强大的方法,用于识别基因组中不仅编码蛋白质重要元素,还控制基因表达和基因组复制的调控区域。
Chapter 3 The Importance of Weak and Strong Chemical Bonds
Original Text
Many important chemical events in cells do not involve the making or breaking of covalent bonds. The cellular location of most molecules depends on weak, or secondary, attractive or repulsive forces. In addition, weak bonds are important in determining the shape of many molecules, especially very large ones. The most important of these weak forces are hydrogen bonds, van der Waals interactions, hydrophobic bonds, and ionic bonds. Even though these forces are relatively weak, they are still large enough to ensure that the right molecules (or atomic groups) interact with each other. For example, the surface of an enzyme is uniquely shaped to allow the specific attraction of its substrates.
The formation of all chemical bonds—weak interactions as well as strong covalent bonds—proceeds according to the laws of thermodynamics. A bond tends to form when the result would be a release of free energy (negative $\Delta$G). For the bond to be broken, this same amount of free energy must be supplied. Because the formation of covalent bonds between atoms usually involves a very large negative $\Delta$G, covalently bound atoms almost never separate spontane- ously. In contrast, the $\Delta$G values accompanying the formation of weak bonds are only several times larger than the average thermal energy of molecules at physiological temperatures. Single weak bonds are thus frequently being made and broken in living cells.
Molecules having polar (charged) groups interact quite differently from nonpolar molecules (in which the charge is symmetrically distributed). Polar molecules can form good hydrogen bonds, whereas nonpolar molecules can form only van der Waals bonds. The most important polar mole- cule is water. Each water molecule can form four hydrogen bonds to other water molecules. Although polar molecules tend to be soluble in water (to various degrees), nonpolar mol- ecules are insoluble because they cannot form hydrogen bonds with water molecules.
Every distinct molecule has a unique molecular shape that restricts the number of molecules with which it can form strong secondary bonds. Strong secondary interactions de- mand both a complementary (lock-and-key) relationship between the two bonding surfaces and the involvement of many atoms. Although molecules bound together by only one or two secondary bonds frequently fall apart, a collection of these weak bonds can result in a stable aggregate. The fact that double-helical DNA never falls apart spontaneously shows the extreme stability possible in such an aggregate.
The biosynthesis of many molecules appears, at a superfi- cial glance, to violate the thermodynamic law that spontane- ous reactions always involve a decrease in free energy ($\Delta$G is negative). For example, the formation of proteins from amino acids has a positive $\Delta$G. This paradox is removed when we realize that the biosynthetic reactions do not proceed as ini- tially postulated. Proteins, for example, are not formed from free amino acids. Instead, the precursors are first enzymati- cally converted to high-energy activated molecules, which, in the presence of a specific enzyme, spontaneously unite to form the desired biosynthetic product.
Many biosynthetic processes are thus the result of “coupled” reactions, the first of which supplies the energy that allows the spontaneous occurrence of the second reac- tion. The primary energy source in cells is ATP. It is formed from ADP and inorganic phosphate, either during degrada- tive reactions (such as fermentation or respiration) or during photosynthesis. ATP contains several high-energy bonds whose hydrolysis has a large negative DG. Groups linked by high-energy bonds are called high-energy groups. High- energy groups can be transferred to other molecules by group-transfer reactions, thereby creating new high-energy compounds. These derivative high-energy molecules are then the immediate precursors for many biosynthetic steps.
Amino acids are activated by the addition of an AMP group, originating from ATP, to form an $AA\sim AMP$ molecule. The energy of the high-energy bond in the $AA\sim AMP$ molecule is similar to that of a high-energy bond of ATP. Nonetheless, the group-transfer reaction proceeds to completion because the high-energy $P - P$ molecule, created when the $AA\sim AMP$ molecule is formed, is broken down by the enzyme pyrophosphatase to low-energy groups. Thus, the reverse reaction, $P - P+AA\sim AMP \rightarrow ATP + AA$, cannot occur.
Almost all biosynthetic reactions result in the release of $P - P$. Almost as soon as it is made, it is enzymatically broken down to two phosphate molecules, thereby making a reversal of the biosynthetic reaction impossible. The great utility of the $P - P$ split provides an explanation for why ATP, not ADP, is the primary energy donor. ADP cannot transfer a high-energy group and at the same time produce $P - P$ groups as a by-product.
Translated Text
许多细胞内的重要化学事件并不涉及共价键的形成或断裂。大多数分子的细胞位置依赖于弱的或次级的吸引或排斥力。此外,弱键在决定许多分子的形状,尤其是非常大的分子时也起着重要作用。这些弱力中最重要的包括氢键、范德华相互作用、疏水键和离子键。尽管这些力相对较弱,但它们仍然足够强大,以确保正确的分子(或原子团)相互作用。例如,酶的表面具有独特的形状,以便特异性地吸引其底物。
所有化学键的形成——无论是弱相互作用还是强共价键——都遵循热力学定律。当形成的结果是释放自由能(负的 $\Delta$G)时,键就倾向于形成。要打破这个键,必须提供相同数量的自由能。由于原子之间共价键的形成通常涉及非常大的负 $\Delta$G,因此共价结合的原子几乎从不自发分离。相反,伴随弱键形成的 $\Delta$G 值仅比生理温度下分子的平均热能大几倍。因此,单个弱键在活细胞中经常被形成和断裂。
具有极性(带电)基团的分子与非极性分子(电荷均匀分布)之间的相互作用截然不同。极性分子能够形成良好的氢键,而非极性分子只能形成范德华键。最重要的极性分子是水。每个水分子可以与其他水分子形成四个氢键。尽管极性分子往往在水中可溶(程度各异),但非极性分子则不溶,因为它们无法与水分子形成氢键。
每个独特的分子都有一个独特的分子形状,这限制了它可以形成强次级键的分子数量。强次级相互作用要求两个结合表面之间存在互补(锁和钥匙)关系,并且涉及许多原子。尽管仅由一两个次级键结合在一起的分子常常会分开,但这些弱键的集合可以形成一个稳定的聚集体。双螺旋 DNA 从不自发分开的事实显示了这种聚集体可能具有的极端稳定性。
许多分子的生物合成在表面上似乎违反了热力学定律,即自发反应总是涉及自由能的减少($\Delta$G 为负)。例如,氨基酸形成蛋白质的过程具有正的 $\Delta$G。当我们意识到生物合成反应并不是最初假设的那样进行时,这一悖论就被消除了。例如,蛋白质并不是由游离氨基酸形成的。相反,前体首先被酶催化转化为高能激活分子,然后在特定酶的存在下,自发结合形成所需的生物合成产物。
因此,许多生物合成过程是“耦合”反应的结果,其中第一个反应提供能量,使第二个反应自发发生。细胞中的主要能量来源是 ATP。它是由 ADP 和无机磷酸盐形成的,发生在降解反应(如发酵或呼吸)或光合作用过程中。ATP 含有几个高能键,其水解具有较大的负 $\Delta$G。通过高能键连接的基团称为高能基团。高能基团可以通过基团转移反应转移到其他分子,从而创造新的高能化合物。这些衍生的高能分子随后是许多生物合成步骤的直接前体。
氨基酸通过添加来自 ATP 的 AMP 基团被激活,形成 $AA\sim AMP$ 分子。$AA\sim AMP$ 分子中高能键的能量与 ATP 的高能键相似。尽管如此,基团转移反应仍然会进行到底,因为在形成 $AA\sim AMP$ 分子时产生的高能 $P - P$ 分子被酶焦磷酸酶分解为低能基团。因此,反向反应 $P - P + AA\sim AMP \rightarrow ATP + AA$ 无法发生。
几乎所有的生物合成反应都会释放 $P - P$。几乎在它形成后不久,它就被酶催化分解为两个磷酸分子,从而使生物合成反应的逆过程变得不可能。$P - P$ 的分裂具有极大的实用性,这解释了为什么 ATP 而不是 ADP 是主要的能量供体。ADP 不能转移高能基团,同时又产生 $P - P$ 基团作为副产物。
Chapter 4 The Structure of DNA
Original Text
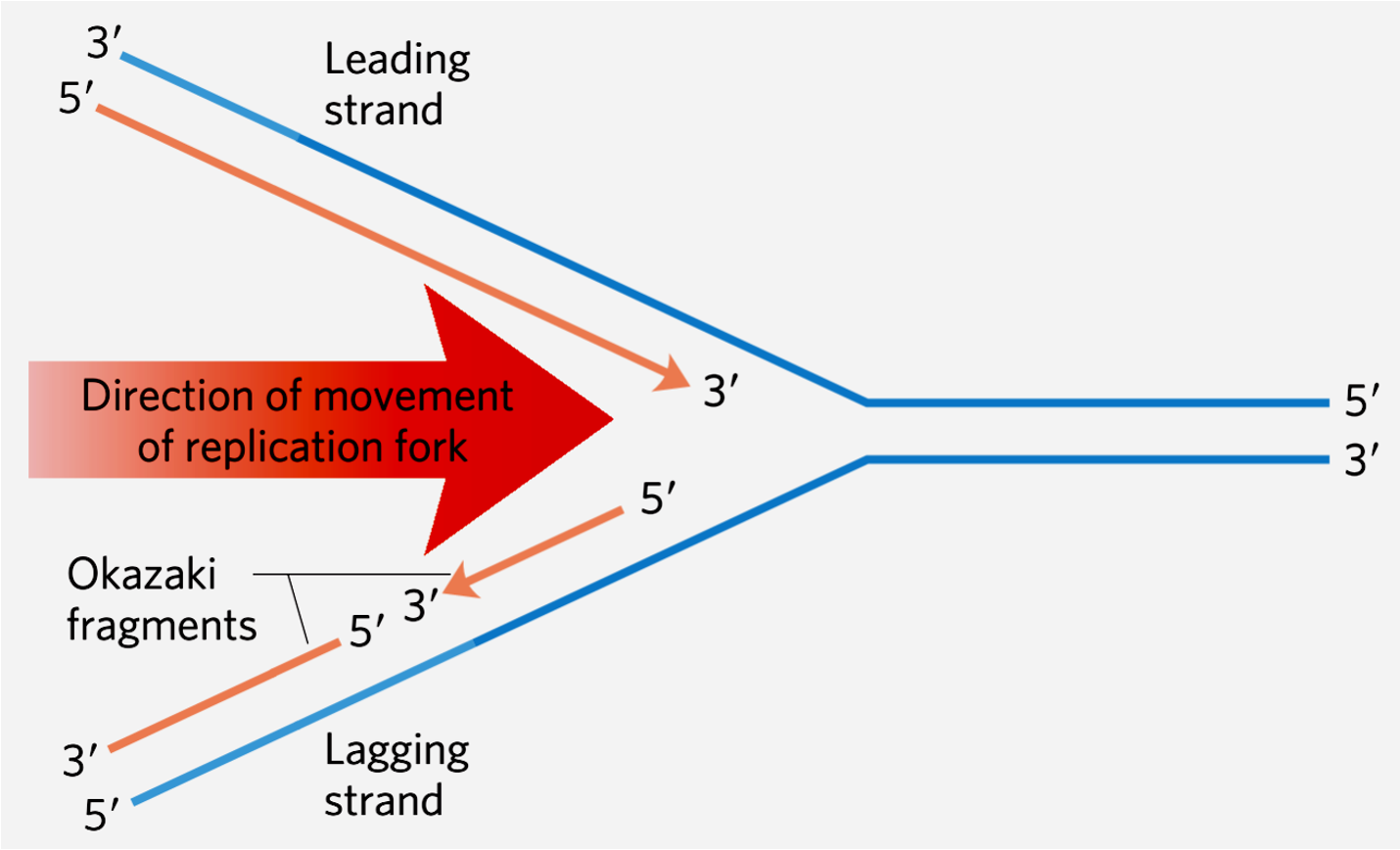
DNA is usually in the form of a right-handed double helix. The helix consists of two polydeoxynucleotide chains. Each chain is an alternating polymer of deoxyribose sugars and phosphates that are joined together via phosphodiester linkages. One of four bases protrudes from each sugar: adenine and guanine, which are purines, and thymine and cytosine, which are pyrimidines. Although the sugar – phosphate backbone is regular, the order of bases is irregular, and this is responsible for the information content of DNA. Each chain has a $5^\prime$ to $3^\prime$ polarity, and the two chains of the double helix are oriented in an antiparallel manner—that is, they run in opposite directions.
The polynucleotide chains are held together by base pairing and base stacking. Pairing is mediated by hydrogen bonds and results in the release of water molecules, increasing entropy. Base stacking also contributes to the stability of the double helix by favorable electron cloud interactions between the bases (van der Waals forces) and by burying the hydrophobic surfaces of the bases (the hydro- phobic effect).
Hydrogen bonding is specific: Adenine on one chain is paired with thymine on the other chain, whereas guanine is paired with cytosine. This strict base pairing reflects the fixed locations of hydrogen atoms in the purine and pyrimidine bases in the forms of those bases found in DNA. Adenine and cytosine almost always exist in the amino as opposed to the imino tautomeric form, whereas guanine and thymine almost always exist in the keto as opposed to enol form. The complementarity between the bases on the two strands gives DNA its self-coding character.
The two strands of the double helix fall apart (denature) upon exposure to high temperature, extremes of pH, or any agent that causes the breakage of hydrogen bonds. Following slow return to normal cellular conditions, the denatured single strands can specifically reassociate to biologically active double helices (renature or anneal).
DNA in solution has a helical periodicity of 10.5 bp per turn of the helix. The stacking of base pairs upon each other creates a helix with two grooves. Because the sugars protrude from the bases at an angle of $\sim 120°$, the grooves are unequal in size. The edges of each base pair are exposed in the grooves, creating a pattern of hydrogen-bond donors and acceptors and of hydrophobic groups that identifies the base pair. The wider—or major—groove is richer in chemical information than the narrow—or minor—groove and is more important for recognition by nucleotide sequence-specific binding proteins.
Almost all cellular DNAs are extremely long molecules, with only one DNA molecule within a given chromosome. Eukaryotic cells accommodate this extreme length in part by wrapping the DNA around protein particles known as nucleosomes. Most DNA molecules are linear, but some DNAs are circles, as is often the case for the chromosomes of prokaryotes and for certain viruses.
DNA is flexible. Unless the molecule is topologically con- strained, it can freely rotate to accommodate changes in the number of times the two strands twist about each other. DNA is topologically constrained when it is in the form of a covalently closed circle or when it is entrained in chromatin. The linking number is an invariant topological property of covalently closed, circular DNA. It is the number of times one strand would have to be passed through the other strand in order to separate the two circular strands. The linking num- ber is the sum of two interconvertible geometric properties: twist, which is the number of times the two strands are wrapped around each other; and the writhing number, which is the number of times the long axis of the DNA crosses over itself in space. DNA is relaxed under physiological conditions when it has 10.5 bp per turn and is free of writhe. If the link- ing number is decreased, then the DNA becomes torsionally stressed, and it is said to be negatively supercoiled. DNA in cells is usually negatively supercoiled by $\sim 6\%$.
The left-handed wrapping of DNA around nucleosomes introduces negative supercoiling in eukaryotes. In prokary- otes, which lack histones, the enzyme DNA gyrase is responsi- ble for generating negative supercoils. DNA gyrase is a member of the type II family of topoisomerases. These enzymes change the linking number of DNA in steps of two by making a transi- ent break in the double helix and passing a region of duplex DNA through the break. Some type II topoisomerases relax supercoiled DNA, whereas DNA gyrase generates negative supercoils. Type I topoisomerases also relax supercoiled DNAs but do so in steps of one in which one DNA strand is passed through a transient nick in the other strand.
Translated Text
DNA 通常以右手螺旋双螺旋的形式存在。该螺旋由两条多脱氧核苷酸链组成。每条链是由脱氧核糖和磷酸交替组成的聚合物,这些单元通过磷酸二酯键连接在一起。每个糖分子上都有四种碱基中的一种突出:腺嘌呤(adenine)和鸟嘌呤(guanine),它们是嘌呤(purines),而胸腺嘧啶(thymine)和胞嘧啶(cytosine)则是嘧啶(pyrimidines)。尽管糖-磷酸骨架是规则的,但碱基的顺序是不规则的,这正是 DNA 信息内容的来源。每条链具有 $5^\prime$ 到 $3^\prime$ 的极性,双螺旋的两条链以反平行的方式定向——也就是说,它们朝相反的方向延伸。
多核苷酸链通过碱基配对和碱基堆叠相互结合。配对是通过氢键介导的,并导致水分子的释放,从而增加熵。碱基堆叠也通过碱基之间的有利电子云相互作用(范德华力)和掩埋碱基的疏水表面(疏水效应)来增强双螺旋的稳定性。
氢键结合是特异性的:一条链上的腺嘌呤与另一条链上的胸腺嘧啶配对,而鸟嘌呤则与胞嘧啶配对。这种严格的碱基配对反映了在 DNA 中发现的嘌呤和嘧啶碱基的氢原子固定位置。腺嘌呤和胞嘧啶几乎总是以氨基形式存在,而不是亚氨基形式;而鸟嘌呤和胸腺嘧啶几乎总是以酮形式存在,而不是烯醇形式。两条链上碱基之间的互补性赋予了 DNA 自我编码的特性。
双螺旋的两条链在高温、极端 pH 或任何导致氢键断裂的因素作用下会分开(变性)。在缓慢恢复到正常细胞条件后,变性的单链可以特异性地重新结合形成生物活性的双螺旋(复性或退火)。
溶液中的 DNA 每转有 10.5 个碱基对的螺旋周期性。碱基对的堆叠形成了一个具有两个沟槽的螺旋。由于糖以约 $120°$ 的角度从碱基突出,因此沟槽的大小不相等。每个碱基对的边缘在沟槽中暴露,形成氢键供体和受体以及疏水基团的模式,从而识别碱基对。较宽的(或称为主要)沟槽比较窄的(或称为次要)沟槽含有更多的化学信息,并且在核苷酸序列特异性结合蛋白的识别中更为重要。
几乎所有细胞 DNA 都是极长的分子,每个染色体中只有一条 DNA 分子。真核细胞通过将 DNA 包裹在称为核小体的蛋白质颗粒周围来部分适应这种极端长度。大多数 DNA 分子是线性的,但某些 DNA 是环状的,这在原核生物的染色体和某些病毒中经常出现。
DNA 是灵活的。除非分子在拓扑上受到限制,否则它可以自由旋转,以适应两条链相互扭转的次数变化。当 DNA 以共价闭合的环状形式存在或被包裹在染色质中时,它就会在拓扑上受到限制。连接数是共价闭合环状 DNA 的不变拓扑特性。它是指为了分开两个环状链,一条链必须穿过另一条链的次数。连接数是两个可互换几何特性的总和:扭转数,即两条链缠绕在一起的次数;以及扭曲数,即 DNA 的长轴在空间中交叉自身的次数。在生理条件下,当 DNA 每转有 10.5 个碱基对且没有扭曲时,它是放松的。如果连接数减少,则 DNA 会变得扭转应力,称为负超螺旋。细胞中的 DNA 通常负超螺旋约 $6\%$。
DNA 在核小体周围的左手缠绕引入了真核生物中的负超螺旋。在缺乏组蛋白的原核生物中,酶 DNA 旋转酶(DNA gyrase)负责产生负超螺旋。DNA 旋转酶是 II 型拓扑异构酶家族的成员。这些酶通过在双螺旋中产生瞬时断裂并将一段双链 DNA 通过断裂来改变 DNA 的连接数,步长为二。有些 II 型拓扑异构酶会放松超螺旋 DNA,而 DNA 旋转酶则产生负超螺旋。I 型拓扑异构酶也会放松超螺旋 DNA,但以步长为一的方式进行,其中一条 DNA 链通过另一条链的瞬时缺口。